Correct Me If I'm Wrong: Fixing Grammatical Errors by Preposition Ranking
An outline of the paper: Correct Me If I’m Wrong: Fixing Grammatical Errors by Preposition Ranking, by Roman Prokofyev et al. (CIKM 2014, Shanghai)
The detection and correction of grammatical errors still represent very hard problems for modern error-correction systems. As an example, the top-performing systems at the preposition correction challenge CoNLL-2013 only achieved an F1 score of 17%.
In this paper, we have developed a method to correct prepositional errors made by non-native English speakers by leveraging large-scale n-gram statistics, n-gram association measures, and machine learning techniques. The general system pipeline is shown on a picture below.
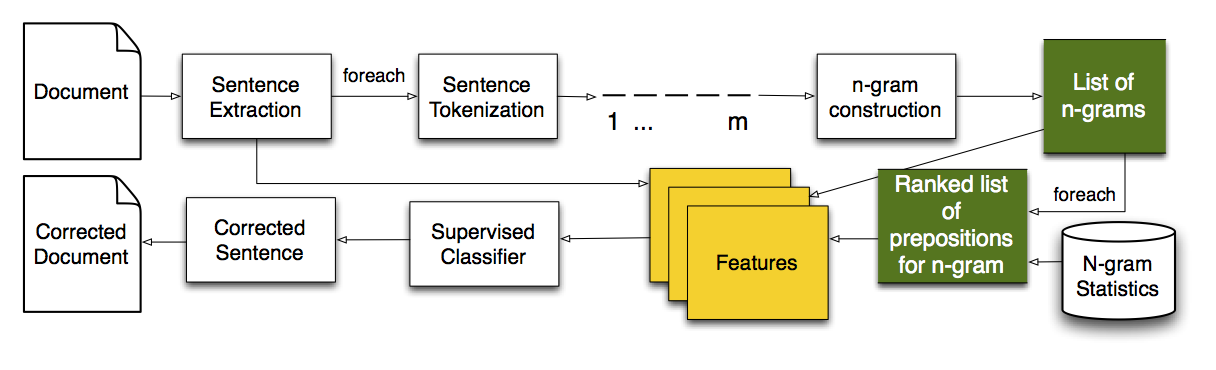
We have evaluated the effectiveness of our approach using cross-validation with different feature combinations and on two test collections created from a set of English essays and StackExchange forums. We also compared it against state-of-the-art supervised methods from CoNLL-2013 challenge. Experimental results obtained on the CoNLL-2013 test collection show that our approach achieved ∼30% in F1 score which is 13% absolute improvement over the best performing approach at that challenge.
The key properties of our system that we think allowed us to outperform the state of art methods are the following:
- Two-class preposition classification on top of PMI-based features;
- Skip n-grams that allow to effectively calculate PMI for 4-grams as if they were 3-grams.
The datasets we used in the paper can be found in a git repository at: https://github.com/XI-lab/preposition-data-cikm2014. Furthermore, we have also implemented the full processing pipeline and packaged in as a convenient library at https://github.com/dragoon/kilogram. The documentation for the library contains links to a set of IPython notebooks that can be used to reproduce our experiments or improve the system further.
The full paper is available online on our website:
Fixing Grammatical Errors by Preposition Ranking.
The conference presentation is available on SlideShare:
http://www.slideshare.net/eXascaleInfolab/cikm14-fixing-grammatical-errors-by-preposition-ranking