Named Entity Recognition for Idiosyncratic Web Collections
An outline of the paper: Effective Named Entity Recognition for Idiosyncratic Web Collections, by Roman Prokofyev et al. (WWW 2014)
Named Entity Recognition (NER) plays an important role in a variety of information management tasks on the Web, including text categorization, document clustering, or faceted search.
In this paper, we have developed a system to identify entities such as original technical concepts in scientific documents. The general system pipeline is shown on a picture below.
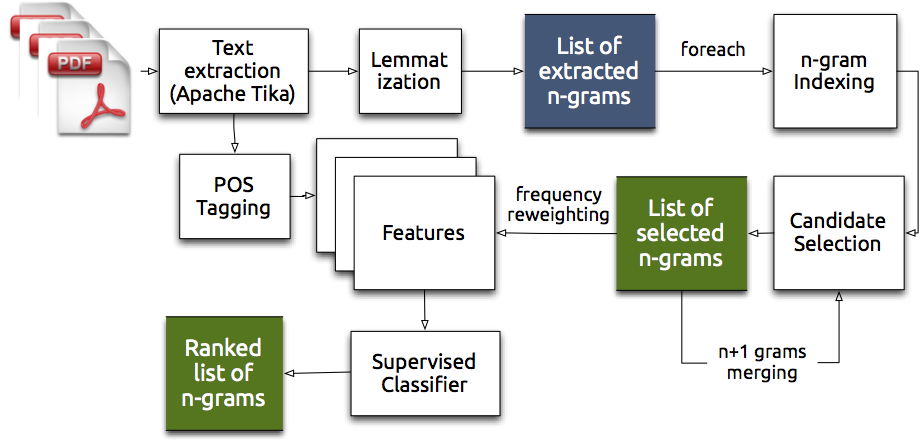
The system was evaluated on two test collections created from a set of Computer Science and Physics papers. Our experimental results have shown ~0.81 Precision and ~0.87 Recall on detecting named entities compared to 0.65/0.72 using state-of-the-art Maximum Entropy methods.
The key properties of our system that we think allowed us to outperform the state of art methods are the following:
- Candidate named entity selection based on n-gram frequency statistics and n-gram merging techniques.
- Candidate named entity classification with features based on external academic knowledge bases such as DBLP and semi-structured knowledge bases such as DBpedia.
The full paper is available online on our website:
Named Entity Recognition for Idiosyncratic Web Collections.