Entities at XI

Entities, intended as concepts in a specified ontology/knowledge based, pervade the Web, texts, and other media.
The final goal of Entities at XI is to exploit entities in order to better retrieve, understand, and summarise information represented by texts and other media.
In order to achieve this goal several steps are needed, in particular, two important tasks needed in order to exploit the information contained in the used knowledge base are:
- identification of the mentions of the entities in the media
- linking of such mentions to the objects in the ontology representing the entities.
The eXascale Infolab is actively involved in both these tasks.
- In “Effective Named Entity Recognition for Idiosyncratic Web Collections” Roman, Gianluca, and Philippe presents a system that exploits n-gram frequency statistics, academic knowledge bases, and general knowledge collections of facts (e.g., DBpedia) to recognise entity mentions in scientific articles (XI Blog post).
- In “Combining Inverted Indices and Structured Search for Ad-Hoc Object Retrieval”, Alberto, Gianluca, and Philippe tackle the problem of linking an entity mention (for example the string “Harry Potter”) to the object in the knowledge base representing the entity, which is often identified by a long and complex URI. As depicted in the following figure, the system we designed to tackle the task uses both an inverted indices built on the literals (strings) of a graph knowledge base to obtain an initial ranked list of candidates entity identifiers, and then exploits an RDF store in order to refine and/or enrich such list of results.
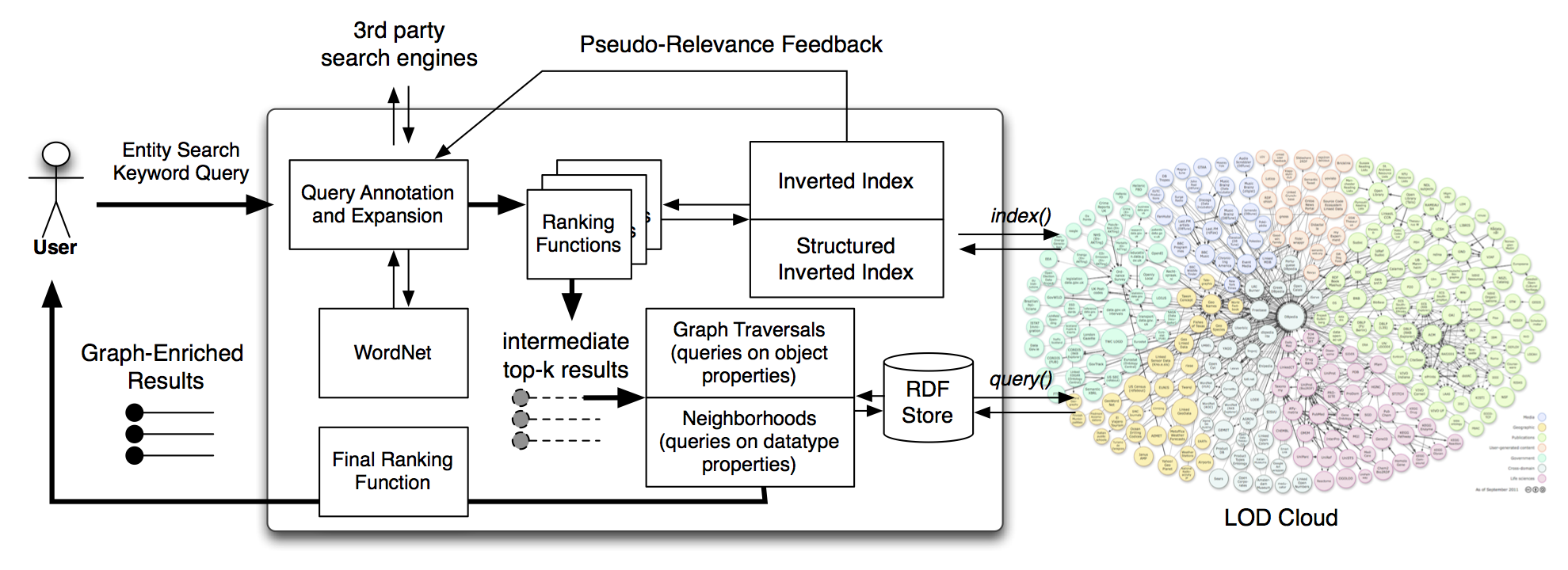
Once an entity mention is linked to its corresponding object in the knowledge base, it is possible to use the facts we know about it.
In this context, XI developed TRank ![]() : A system that exploits state of the art named entity techniques to recognise and link entities in order to get all their types and to rank them according to the context where the entities were mentioned. For example, the entity ‘Barack Obama’ can be mentioned in a Gulf War context or in a golf tournament context. The most relevant type for ‘Barack Obama’ is probably different given one or the other context.
: A system that exploits state of the art named entity techniques to recognise and link entities in order to get all their types and to rank them according to the context where the entities were mentioned. For example, the entity ‘Barack Obama’ can be mentioned in a Gulf War context or in a golf tournament context. The most relevant type for ‘Barack Obama’ is probably different given one or the other context.
TRank exploits the type hierarchy depicted in the following, which is composed by almost 500 000 entity types from DBpedia, YAGO, and schema.org. More details are available in the paper “TRank: Ranking Entity Types Using the Web of Data”; moreover, TRank is open source and its code can be downloaded from https://github.com/MEM0R1ES/TRank.
